llm-routing-bench
A Go-based load balancer for LLM inference servers with pluggable routing strategies and integrated benchmarking. The goal is to measure how different routing strategies affect tail latency (p95/p99) in LLM inference serving.
To read more about this project motivation and system architecture, refer to Research.
Architecture
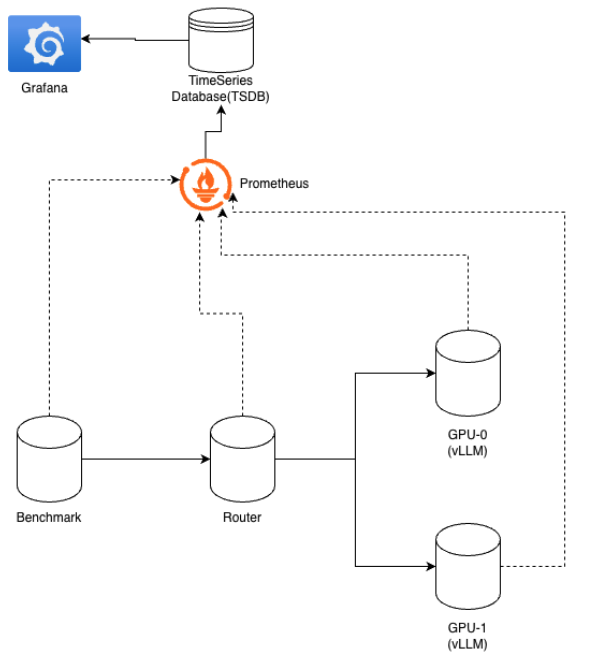
Modes
The router supports two modes, set via the MODE env variable:
server— Proxies POST requests to backend/v1/completions. Requires real vLLM instances and an NVIDIA GPU.local— Proxies GET requests to lightweight fake backends. No GPU required, suitable for development and testing without GPU.
Routing Strategies
| Strategy | Flag | Description |
|---|---|---|
| Round Robin | roundrobin | Cycles through backends sequentially |
| Consistent Hashing | consistanthashing | FNV-32a hash of request URL maps to a backend on a consistent ring |
| Least Queue | leastqueue | Scrapes vllm:num_requests_running from each backend and routes to the least loaded (WIP) |
| Least KV Cache | least-kvcache | TBA |
Where to Go Next
- Prerequisites — what you need before running anything
- Dev Mode — run the stack locally without a GPU
- Production Mode — run with real vLLM on GPU hardware
- Routing Strategies Reference — flag names and behavior details
- Benchmarking — how to run load tests and read the output
- Metrics — Prometheus metrics exposed by the router